Topic Modeling
Created by 马明
Content
- LSA Introduction
- LSA in detail
- PLSA
- LDA
LSA Introduction
- Latent Semantic Analysis is a technique for creating a vector representation of a document.
- Often apply for text clustering, classification and Topic Modeling
What is Topic Modeling
Basic assumption
- Each document consists of a mixture of topics
- Each topic consists of a collection of words
What LSA can do?
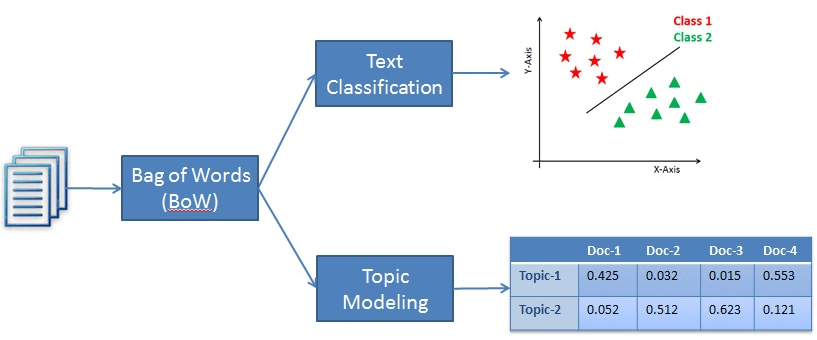
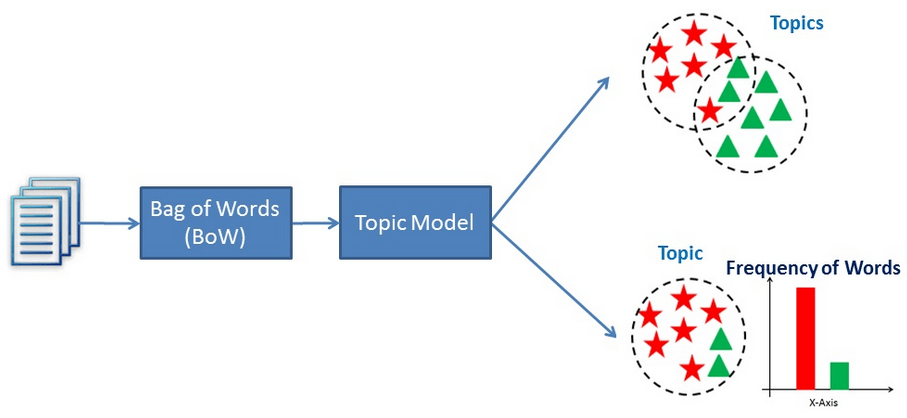
The key is Find the Latent Variable!!!
LSA In Detail
Recall TF-IDF
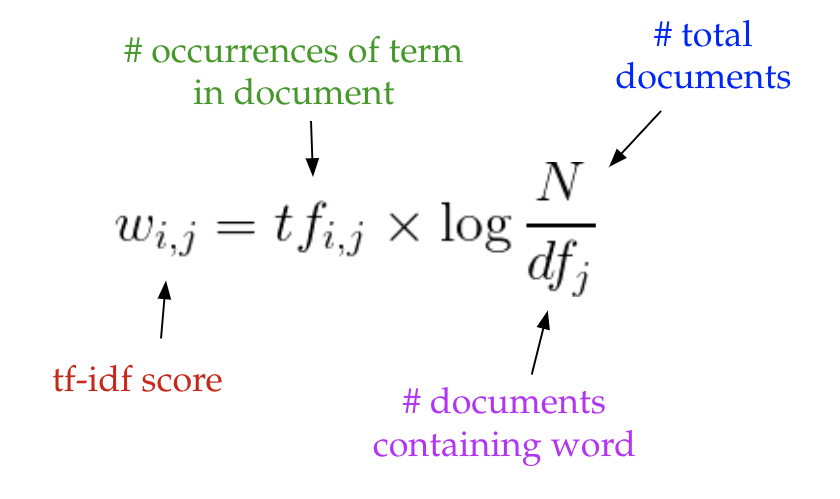
We can get matrix A for words to documents, every cell is the tf-idf score
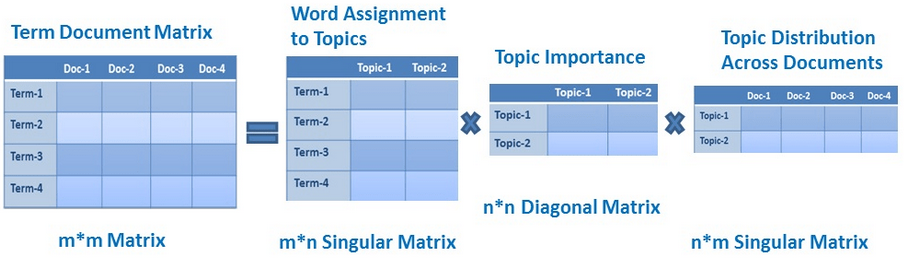
Matrix A is sparse and noisy, we need dimensionality reduction on A
$$M=U\Sigma V^T$$
- M is an m×m matrix
- U is a m×n left singular matrix
- Σ is a n×n diagonal matrix with non-negative real numbers.
- V is a m×n right singular matrix
Truncated SVD

With the document vectors and term vectors, we can apply measures such as cosine similarity to evaluate:
- the similarity of different documents
- the similarity of different words
- the similarity of terms (or “queries”) and documents
Determining optimum number of topics
- Consider each topic as a cluster, find out the effectiveness of a cluster using the Silhouette coefficient
- Topic coherence
widely used metric to evaluate topic models
find average/median of pairwise word similarity scores of the words in a topic
LSA is quick and efficient to use, but also with drawbacks:
- Lack of interpretable embeddings
- Need for really large set of documents and vocabulary to get accurate results
- Less efficient representation
PLSA
pLSA, or Probabilistic Latent Semantic Analysis, uses a probabilistic method instead of SVD
The core idea is to find a probabilistic model with latent topics that can generate the data we observe in our document-term matrix
$P(D,W)$ for any document $d$ and word $w$, $P(D,W)$ corresponds to that entry in the document-term matrix
- given a document d, topic z is present in that document with probability P(z|d)
- given a topic z, word w is drawn from z with probability P(w|z)
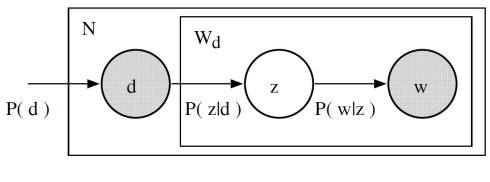
The joint probability of seeing a given document and word together:
$$P(D,W)=P(D)\sum_{Z}P(Z|D)P(W|Z)$$
$P(D), P(Z|D), and\ P(W|Z)$ are parameters
$P(D)$ can be determined directly from our corpus
$P(Z|D)\ and\ P(W|Z)$ are modeled as multinomial distributions, and can be trained using the expectation-maximization algorithm (EM)
$$P(D,W)=\sum_{Z}P(Z)P(D|Z)P(W|Z)$$
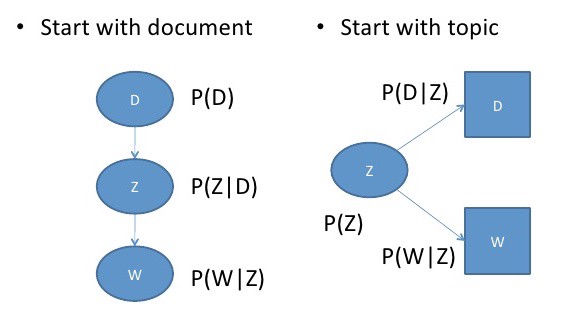
Relation between pLSA and LSA
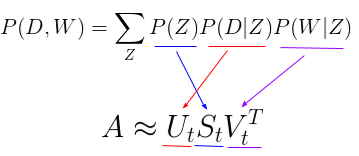
Drawbacks of pLSA
Because we have no parameters to model $P(D)$ , we don’t know how to assign probabilities to new documents.
The number of parameters for pLSA grows linearly with the number of documents we have, so it is prone to overfitting
LDA
LDA stands for Latent Dirichlet Allocation
LDA is a Bayesian version of pLSA
Dirichlet priors for the document-topic and word-topic distributions, lending itself to better generalization
- Big Idea:
Each document can be described by a distribution of topics
Each topic can be described by a distribution of words
What the LATENT means?
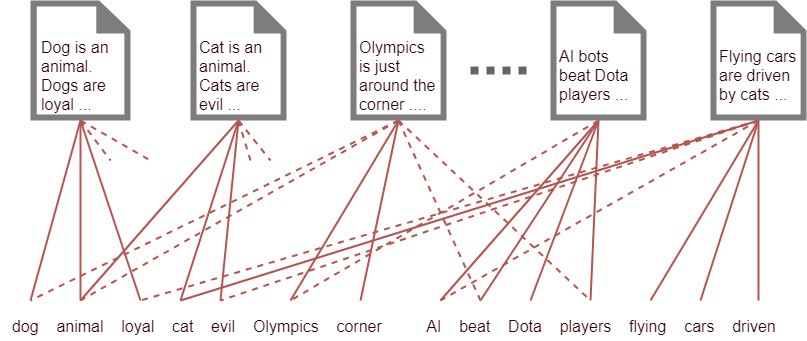
- You have 1000 words and 1000 documents
- Each document on average has 500 of these words appearing in each
How can you understand what category each document belongs to?
500*1000 = 500,000 threads
The Topic is LATENT
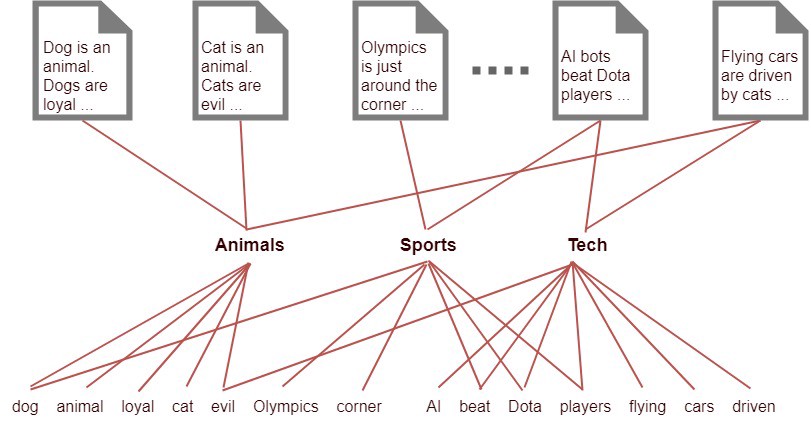
- Introducing LATENT layer with 5 topics
- Reducing to 1000*5*2 = 10,000 threads
What is the Dirichlet Distribution
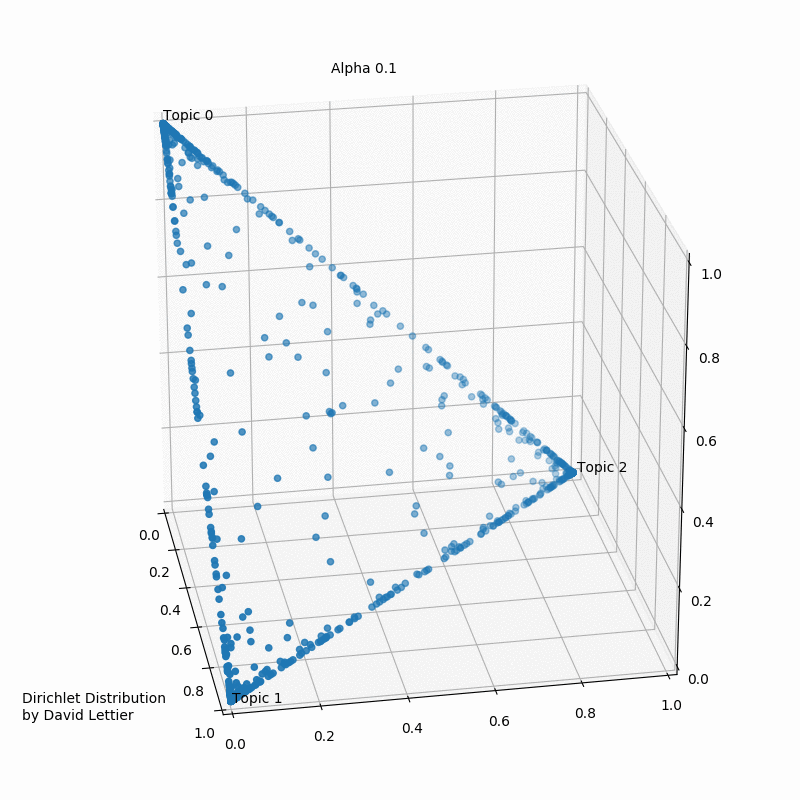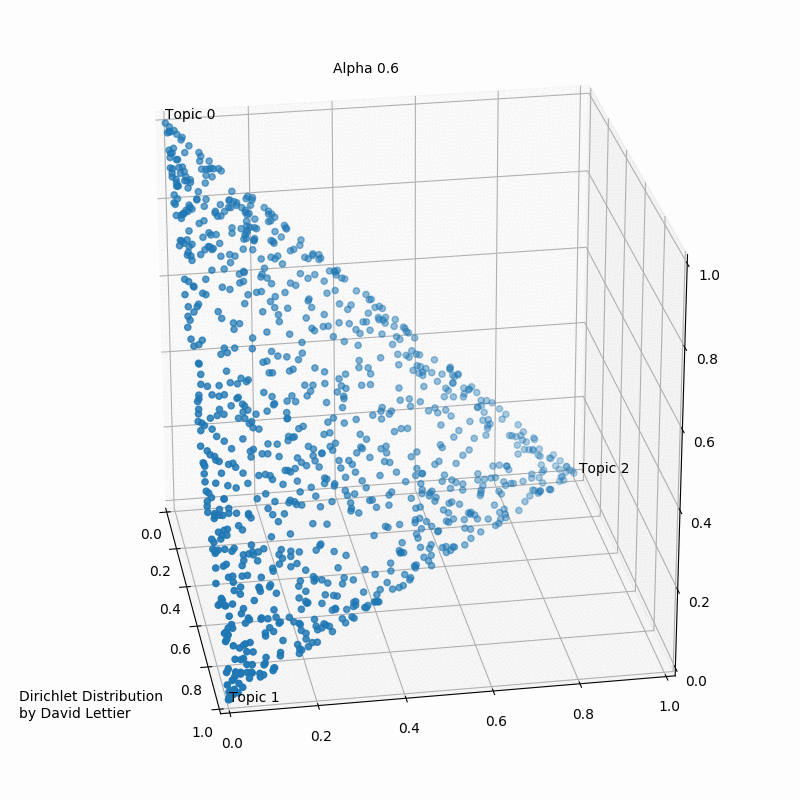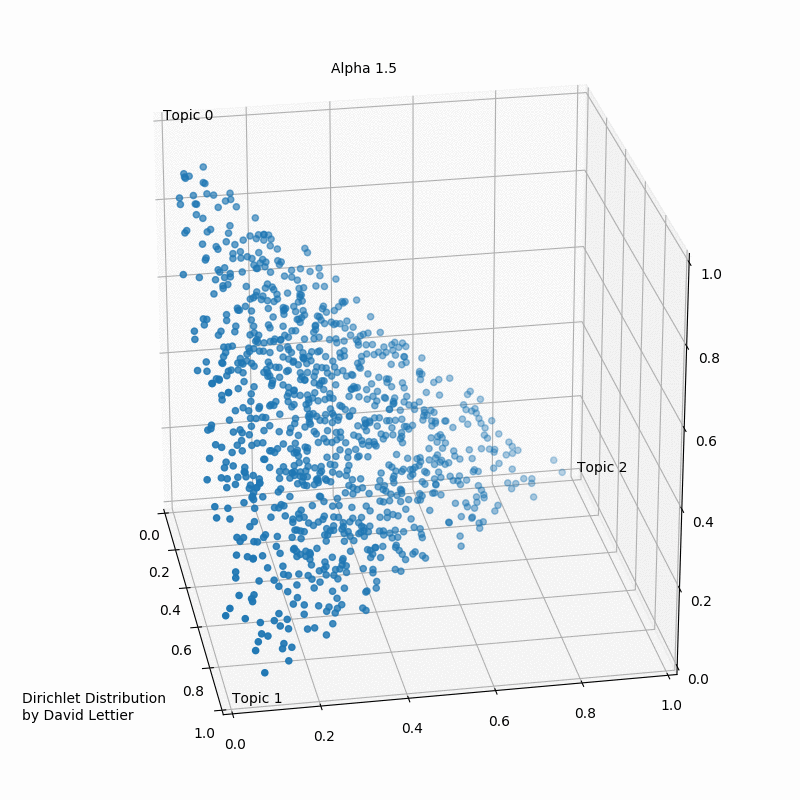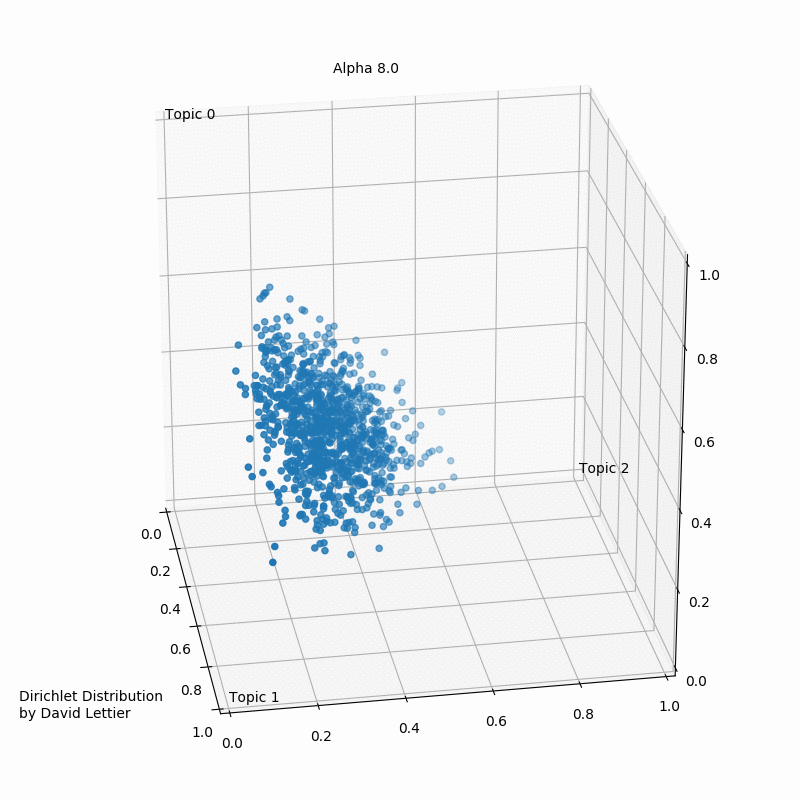
- The Dirichlet distribution defines a probability density for a vector
- $x_1,\cdots,x_k$, where $x_i \in (0,1)$ and $\sum_{i=1}^k x_i =1$
- $PDF=\frac{1}{B(\alpha)}\prod_{i=1}^{k} x_i^{\alpha_i-1}$
- where $B(\alpha)=\frac{\prod_{i=1}^k\Gamma(\alpha_i)}{\Gamma(\sum_{i=1}^k \alpha_i)}$
- where $\alpha=(\alpha_i,\cdots,\alpha_k)$
- $E[x_i]=\frac{\alpha_i}{\sum_j \alpha_j}$
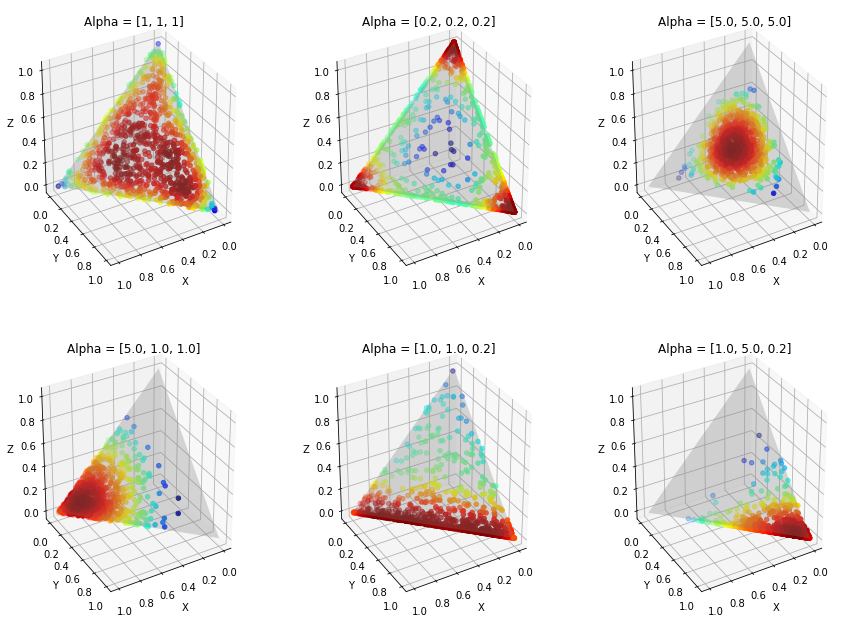
- $\theta_i \sim Dir(\alpha)$, $i=1,...,M$
- $\theta_{i,k}=$ probability that document $i \in \{1,...,M\}$ has topic $k \in \{1,...,K\}$
- $\phi_k \sim Dir(\beta), k=1,...,K$
- $\phi_{k,v}=$ probability of word $v \in \{1,...,V\}$ in topic $k \in \{1,...,K\}$
- Choose $z_{i,j} \sim Multinominal(\theta_i), z_{i,j} \in \{1,...,K\}$
- Choose $w_{i,j} \sim Multinominal(\phi_{i,j}), w_{i,j} \in \{1,...,V\}$
How LDA imagine documents are generated?
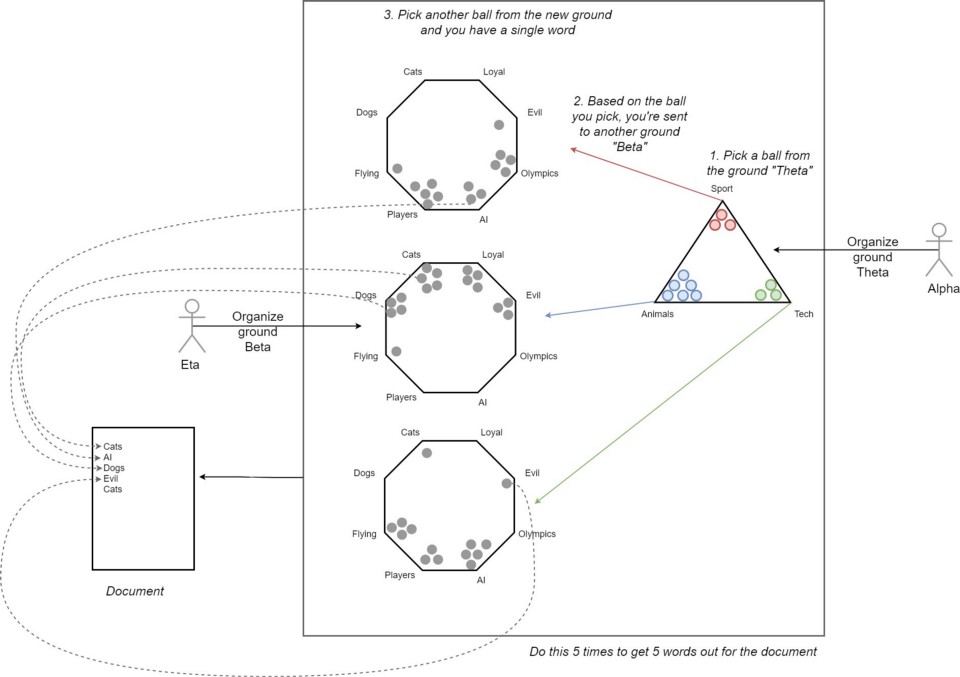
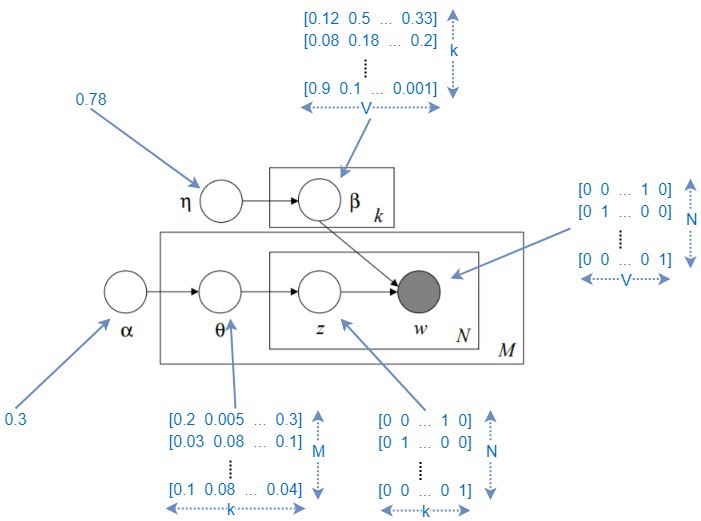
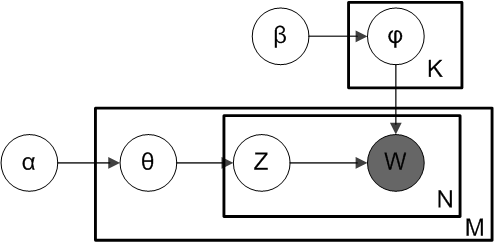
How Do We Learn LDA
$$P(\theta_{1:M},z_{1:M},\beta_{1:k}|D;\alpha_{1:M},\phi_{1:k})$$
- $\alpha$: Distribution related parameter that governs what the distribution of topics is for all the documents
- $\theta$: $\theta(i,j)$ represents the probability of the i th document to containing the j th topic.
- $\phi$: Distribution related parameter that governs what the distribution of words in each topic
- $\beta$: $\beta(i,j)$ represents the probability of i th topic containing the j th word
How to solve it?
Variational inference
Approximate the messy intractable posterior with some known probability distribution that closely matches the true posterior
minimise the KL divergence
$\gamma^*,\phi^*,\lambda^*=argmin_{\gamma,\phi,\lambda}D(q(\theta,z,\beta|\gamma,\phi,\lambda)||p(\theta,z,\beta|D,\alpha,\eta))$
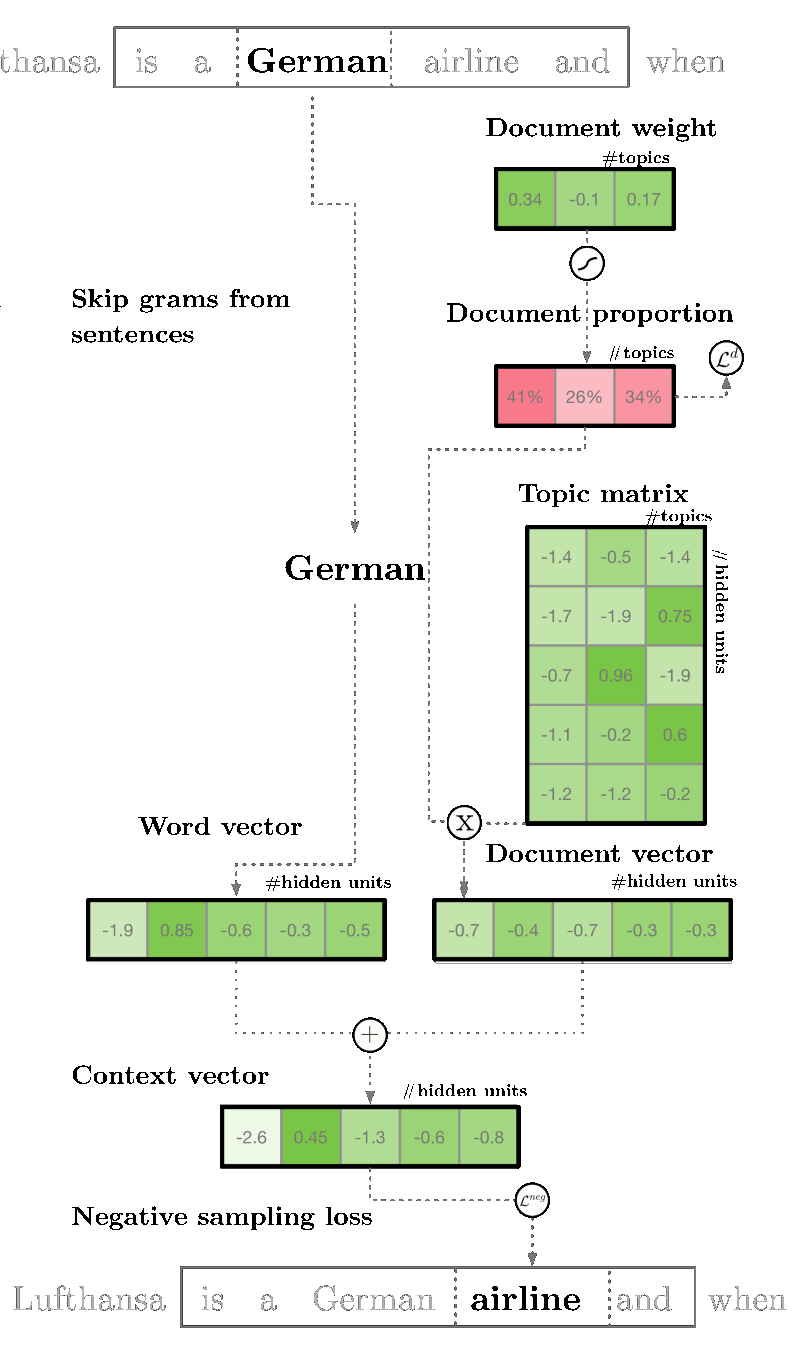
LDA in Deep Learning: lda2vec
lda2vec is an extension of word2vec and LDA that jointly learns word, document, and topic vectors.
Key points of lda2vec
- Leverage a context vector
- The context vector = word vector + document vector
word vector = skip-gram word2vec model
document weight vector: representing the “weights” of each topic in the document
topic matrix: representing each topic and its corresponding vector embedding
Markdown support
Write content using inline or external Markdown. Instructions and more info available in the readme.
<section data-markdown>
## Markdown support
Write content using inline or external Markdown.
Instructions and more info available in the [readme](https://github.com/hakimel/reveal.js#markdown).
</section>
Fragments
Hit the next arrow...
... to step through ...
... a fragmented slide.
Fragment Styles
There's different types of fragments, like:
grow
shrink
fade-out
fade-up (also down, left and right!)
current-visible
Highlight red blue green
Transition Styles
You can select from different transitions, like:
None -
Fade -
Slide -
Convex -
Concave -
Zoom
Themes
reveal.js comes with a few themes built in:
Black (default) -
White -
League -
Sky -
Beige -
Simple
Serif -
Blood -
Night -
Moon -
Solarized
Slide Backgrounds
Set data-background="#dddddd" on a slide to change the background color. All CSS color formats are supported.
Image Backgrounds
<section data-background="image.png">Tiled Backgrounds
<section data-background="image.png" data-background-repeat="repeat" data-background-size="100px">Video Backgrounds
<section data-background-video="video.mp4,video.webm">... and GIFs!
Background Transitions
Different background transitions are available via the backgroundTransition option. This one's called "zoom".
Reveal.configure({ backgroundTransition: 'zoom' })Background Transitions
You can override background transitions per-slide.
<section data-background-transition="zoom">Pretty Code
function linkify( selector ) {
if( supports3DTransforms ) {
var nodes = document.querySelectorAll( selector );
for( var i = 0, len = nodes.length; i < len; i++ ) {
var node = nodes[i];
if( !node.className ) {
node.className += ' roll';
}
}
}
}Code syntax highlighting courtesy of highlight.js.
Marvelous List
- No order here
- Or here
- Or here
- Or here
Fantastic Ordered List
- One is smaller than...
- Two is smaller than...
- Three!
Tabular Tables
| Item | Value | Quantity |
|---|---|---|
| Apples | $1 | 7 |
| Lemonade | $2 | 18 |
| Bread | $3 | 2 |
Clever Quotes
These guys come in two forms, inline: The nice thing about standards is that there are so many to choose from
and block:
“For years there has been a theory that millions of monkeys typing at random on millions of typewriters would reproduce the entire works of Shakespeare. The Internet has proven this theory to be untrue.”
Intergalactic Interconnections
You can link between slides internally, like this.
Speaker View
There's a speaker view. It includes a timer, preview of the upcoming slide as well as your speaker notes.
Press the S key to try it out.
Export to PDF
Presentations can be exported to PDF, here's an example:
Global State
Set data-state="something" on a slide and "something"
will be added as a class to the document element when the slide is open. This lets you
apply broader style changes, like switching the page background.
State Events
Additionally custom events can be triggered on a per slide basis by binding to the data-state name.
Reveal.addEventListener( 'customevent', function() {
console.log( '"customevent" has fired' );
} );Take a Moment
Press B or . on your keyboard to pause the presentation. This is helpful when you're on stage and want to take distracting slides off the screen.
Much more
- Right-to-left support
- Extensive JavaScript API
- Auto-progression
- Parallax backgrounds
- Custom keyboard bindings
THE END

