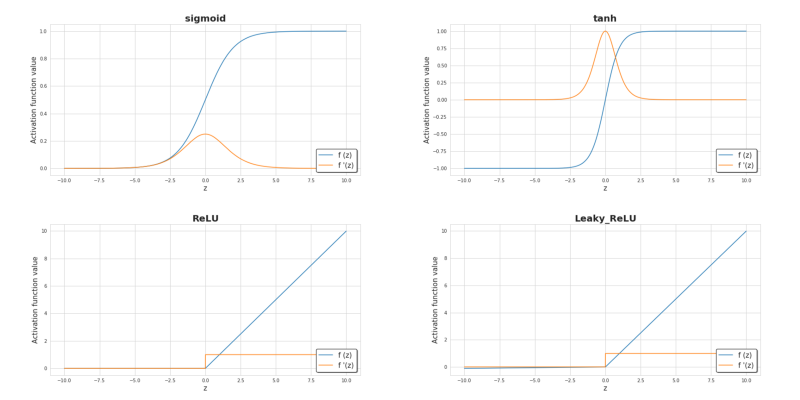
深度神经网络
- Basic Introduction
- Views on DNN
- RGLM
Basic Introduction
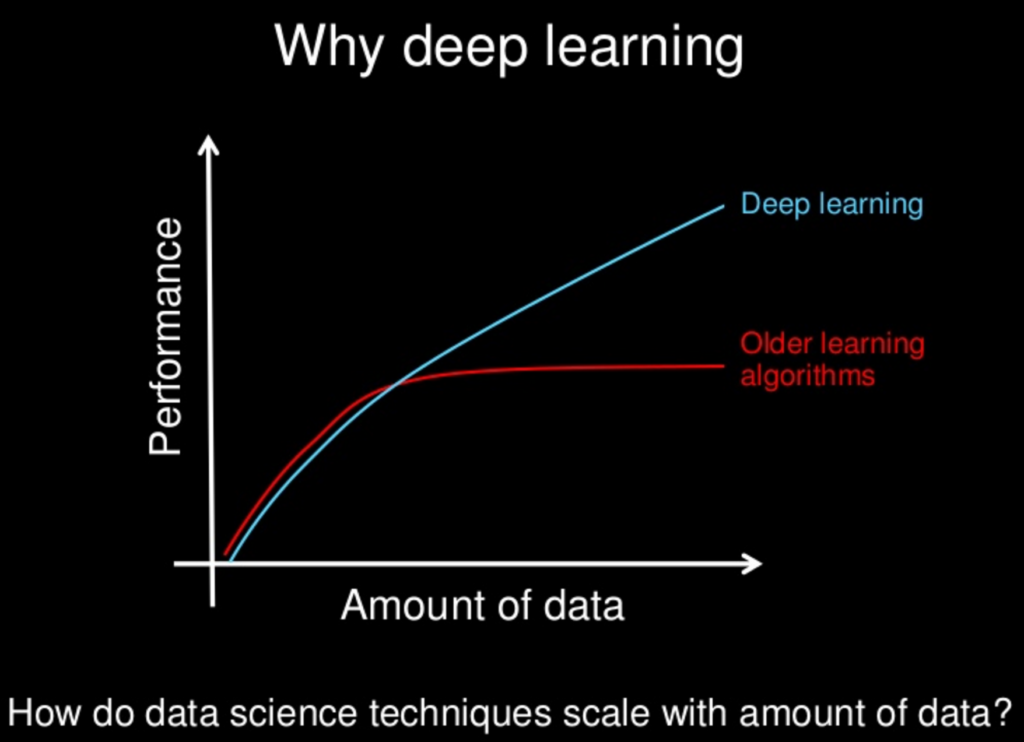

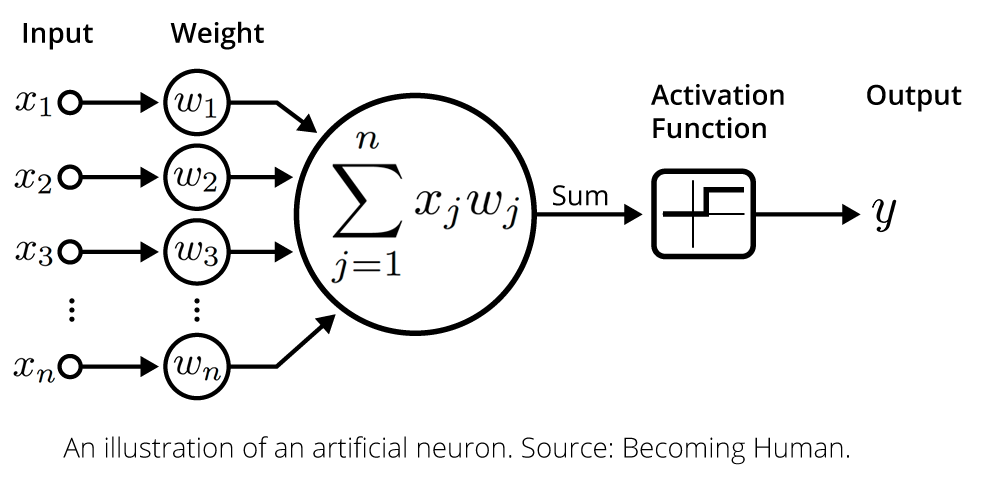
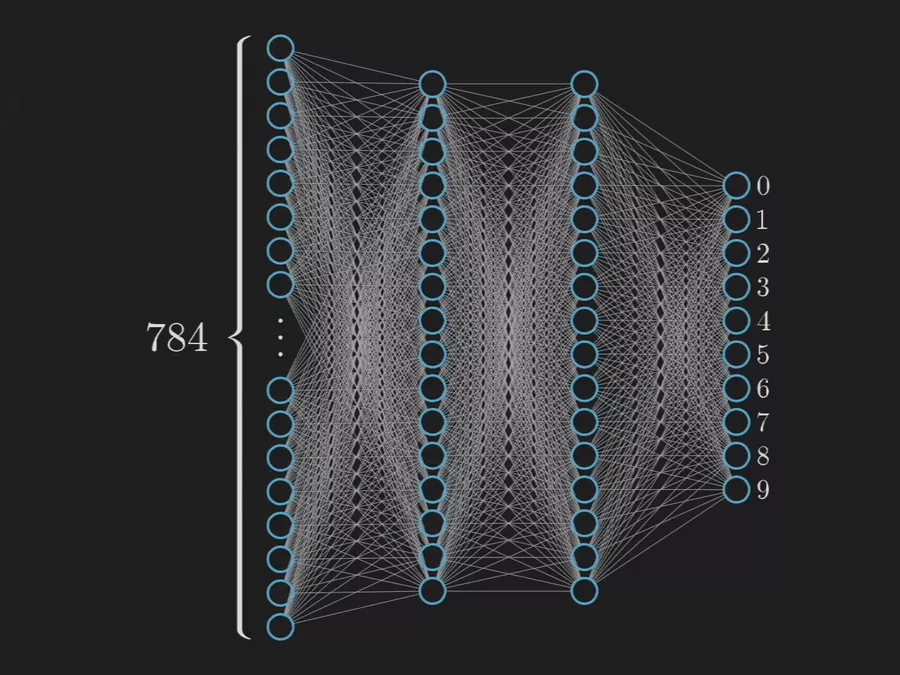
RGLM
Recursive Generalised Linear Model
A Simple Linear Model
$\eta = \beta^\top x + \beta_0$
$y = \eta+\epsilon \qquad \epsilon \sim \mathcal{N}(0,\sigma^2)$
- $\eta$ is the systematic component of the model
- $\epsilon$ is the random component
Generalised linear models (GLMs)
Extend linear model to problems where the distribution on the targets is not Gaussian but some other distribution (typically a distribution in the exponential family)
$\eta = \beta^\top x, \qquad \beta=[\hat \beta, \beta_0], x = [\hat{x}, 1]$
$\mathbb{E}[y] = \mu = g^{-1}(\eta)$
$g(·)$ is the link function

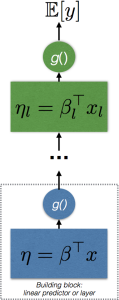
What RGLM means?
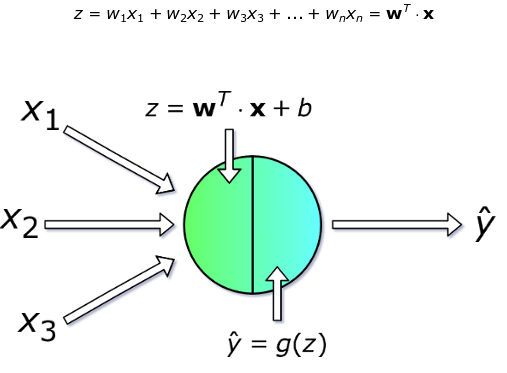
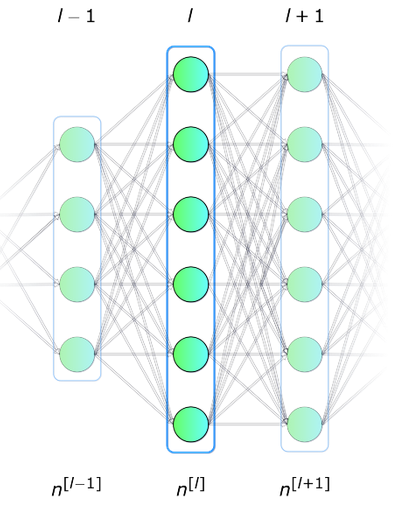
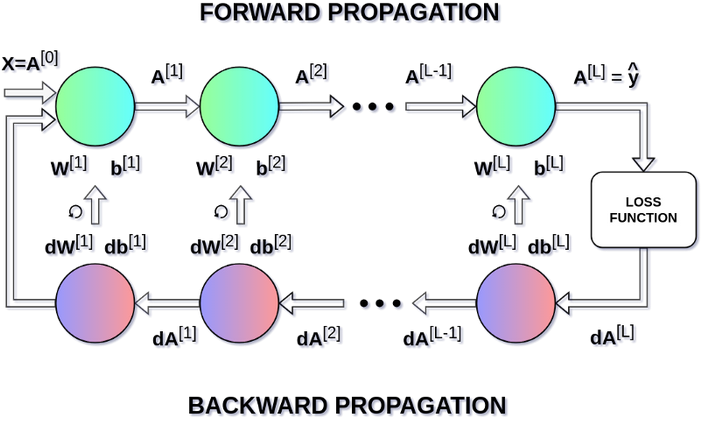
- In deep learning, the basic building block is called a layer.
- Building block can be easily repeated to form more complex, hierarchical and non-linear regression functions
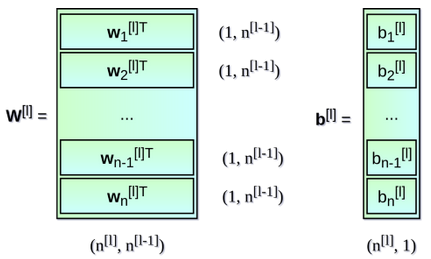
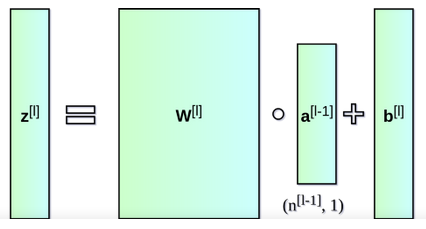
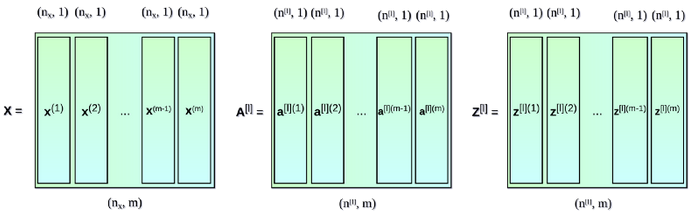
$h_l(x) = f_l(\eta_l)$
$\mathbb{E}[y] = \mu_L = h_L \circ \ldots \circ h_1 \circ h_o(x)$
$\mathcal{L} = - \log p(y | \mu_L)$