"经验风险"最小化分类器
- 最大熵模型
- 逻辑回归的推广
- Softmax回归
- 逻辑回归就是最大熵分类器
思考
最大熵模型
MaxEnt 是概率模型学习中一个准则,其思想为:在学习概率模型时,所有可能的模型中熵最大的模型是最好的模型;若概率模型需要满足一些约束,则最大熵原理就是在满足已知约束的条件集合中选择熵最大模型。
最大熵原理指出,对一个随机事件的概率分布进行预测时,预测应当满足全部已知的约束,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小,因此得到的概率分布的熵是最大
给定训练数据$\left \{ (x_i,y_i)\right\}_{i=1}^N$,现在要通过Maximum Entropy 来建立一个概率判别模型,该模型的任务是对于给定的$X = x$以条件概率分布$P(Y|X = x)$预测Y的取值。
对于随机变量$X = x_i,i = 1,2,…$,
随机变量期望: 其数学期望为$E(X) = \sum_ix_ip_i$
随机变量函数期望:$Y = f(X),\ E(Y) = \sum_if(x_i)p_i$
特征函数$f(x,y)$描述x与y之间的某一事实,其定义如下:$$f(x,y) = \left \{ \begin{aligned} 1, & \ 当 \ x、y \ 满足某一事实.\\ 0, & \ 不满足该事实.\\ \end{aligned}\right .$$
根据训练数据确定联合分布的经验分布$\widetilde{P}(X,Y)$与边缘分布的经验分布$\widetilde{P}(X)$为$$\begin{aligned} \widetilde{P}(X = x,Y = y) &= \frac{count(X=x,Y= y)}{N}\\ \widetilde{P}(X = x) &= \frac{count(X=x)}{N} \end{aligned}$$
用$E _{\widetilde{P}}(f)$表示特征函数$f(x,y)$关于经验分布$\widetilde{P}(X ,Y )$上的期望,有$$E _{\widetilde{P}}(f) = \sum_{x,y}\widetilde{P}(x ,y)f(x,y) = \frac{1}{N} \sum_{x,y}f(x,y)$$
$E_P(f) = E _{\widetilde{P}}(f)$
$\sum_{x,y}\widetilde{P}(x)p(y|x)f(x,y) = \sum_{x,y}\widetilde{P}(x ,y)f(x,y)$
模型$P(Y|X)$的熵为:$H(P) =–\sum_{x,y}P(y,x)logP(y|x)= –\sum_{x,y}\widetilde{P}(x)P(y|x)logP(y|x)$
模型约束条件即为$$\begin{aligned} & \min_{P \in C} \ \ \sum_{x,y} \widetilde{P}(x)P(y|x)logP(y|x) \\ & \ s.t. \ \ \ E_p(f_i) = E _{\widetilde{P}}(f_i) \\ & \ \ \ \ \ \ \ \ \ \sum_yP(y|x) = 1 \end{aligned}$$
MaxEnt模型最后被形式化为带有约束条件的最优化问题,引入拉格朗日乘子$w_0,w_1,…,w_n$,拉格朗日函数为:$$\begin{aligned} L(P,w) &= -H(P) + w_0\left (1-\sum_yP(y|x) \right ) + \sum^n_{i=1}w_i(E _{\widetilde{P}}(f_i) - E_p(f_i))\\ &=\sum_{x,y} \widetilde{P}(x)P(y|x)logP(y|x) + w_0\left (1-\sum_yP(y|x) \right ) + \sum^n_{i=1}w_i\left (\sum_{x,y}\widetilde{P}(x ,y)f(x,y) -\sum_{x,y}\widetilde{P}(x)p(y|x)f(x,y) \right ) \end{aligned}$$
求解后得到:$$\begin{aligned} P_w(y|x) &= \frac{1}{Z_w(x) }exp \left ( \sum_{i=1}^n w_if_i(x,y) \right ) \\ Z_w(x) &=\sum _y exp \left ( \sum_{i=1}^n w_if_i(x,y) \right ) \end{aligned}$$
逻辑回归的推广
逻辑回归是解决二元分类问题,是否可以扩展这种思路来解决多元分类问题呢?
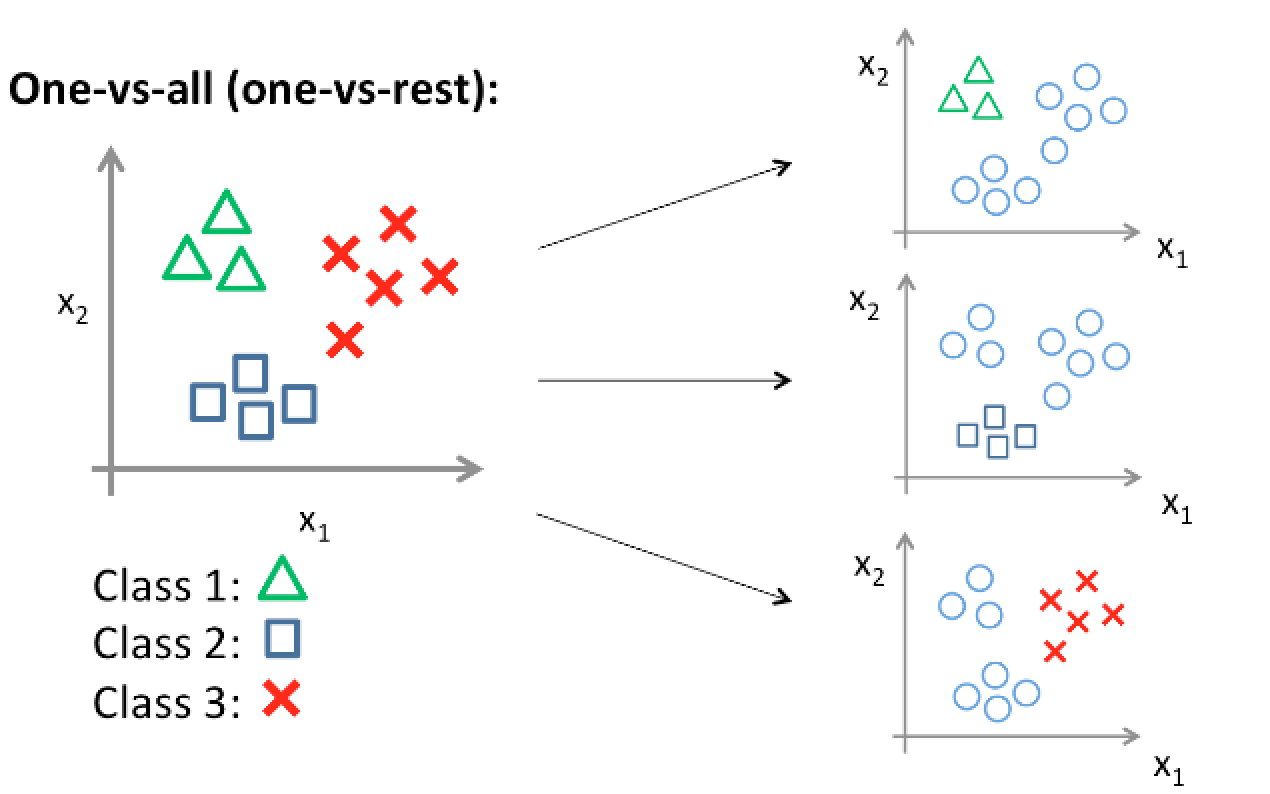
One Vs All (One Vs Rest)
一个基础的想法是把$k$元分类问题理解为$k$个逻辑回归问题
One Vs One (Multinominal logit regression)
第二种思路就是和逻辑回归的建模思路类似,我们从$k$中选取一类作为参考,为每个类建立其对参考类的收益风险比
$$ln\frac{P(Y=1)}{P(Y=K)} = X\beta_1$$ $$ln\frac{P(Y=2)}{P(Y=K)} = X\beta_2$$ ... $$ln\frac{P(Y=K-1)}{P(Y=K)} = X\beta_{K-1}$$
对上面$K-1$个方程取指数,得到:
$$P(Y=1)=P(Y=K)e^{X\beta_1}$$ $$P(Y=2)=P(Y=K)e^{X\beta_2}$$ $$...$$ $$P(Y=K-1)=P(Y=K)e^{X\beta_{K-1}}$$
根据总体概率和为1,可以得到:
$$P(Y=K)=1-\sum_{k=1}^{K-1}P(Y=k)=1-\sum_{k=1}^{K-1}P(Y=K)e^{X\beta_k}$$ $$P(Y=K)=\frac{1}{1+\sum_{k=1}^{K-1}e^{X\beta_k}}$$
最后得到:$$P(Y=1)=\frac{e^{X\beta_1}}{1+\sum_{k=1}^{K-1}e^{X\beta_k}}$$ $$P(Y=2)=\frac{e^{X\beta_2}}{1+\sum_{k=1}^{K-1}e^{X\beta_k}}$$ $$...$$ $$P(Y=K-1)=\frac{e^{X\beta_{K-1}}}{1+\sum_{k=1}^{K-1}e^{X\beta_k}}$$
注意:这种建模方式假设数据和分类符合IIA(Independence of Irrelevance Alternatives)
Softmax回归
回想前面所做的模型推导中,参考类的概率公式形式和其他类的概率公式形式不太一样。
我们设$e^{X\beta_K}=1$,可得:$$P(Y=1)=\frac{e^{X\beta_1}}{\sum_{k=1}^{K}e^{X\beta_k}}$$ $$P(Y=2)=\frac{e^{X\beta_2}}{\sum_{k=1}^{K}e^{X\beta_k}}$$ $$...$$ $$P(Y=K)=\frac{e^{X\beta_{K}}}{\sum_{k=1}^{K}e^{X\beta_k}}$$
联想最大熵模型的结果,可知Softmax回归就是采用的最大熵模型的思想。当$K=2$时就是逻辑回归,也就是说逻辑回归是最大熵分类器的一种特殊形式。